In un precedente articolo abbiamo parlato di ChatGPT, un prototipo di chatbot basato sull'Intelligenza Artificiale e specializzato nella conversazione con un utente umano tramite testo scritto. Il "meccanismo di attenzione neurale" è la componente segreta che rende ChatGPT così naturale da sembrare quasi umano. In questo articolo, cercheremo di capire intuitivamente il meccanismo dell'attenzione, ma per farlo occorrerà rivedere rapidamente il panorama delle architetture di elaborazione del linguaggio naturale (PNL) nell'ultimo decennio.
Introduzione
Lo sviluppo del percettrone multistrato ha permesso di impilare più percettroni e organizzarli in strati, per creare modelli che rappresentino al meglio problemi complessi. Il percettrone multistrato opera in modo discreto e atemporale, ma molti problemi del mondo reale coinvolgono una dimensione temporale. Questa tipologia di percettrone si può usare per l'attività di Sentiment Analysis, ovvero, per identificare ed estrarre le opinioni da un testo, ad esempio per capire se le recensioni di una struttura ricettiva sono positive o negative. Il percettrone multistrato utilizzerà come input il vettore costituito dalle parole tokenizzate di ogni recensione, ma considererà ogni recensione come una singola unità (frase), e non come una sequenza di tante unità (parole). Mentre un modo più accurato di effettuare la Sentiment Analysis potrebbe essere quello di considerare la posizione di ogni parola nella recensione, perché la struttura di una frase svolge un ruolo importante nel suo significato. Ad esempio, frasi come "Questa volta il servizio è stato ottimo" e "Ottimo servizio questa volta", esprimono la stessa opinione, anche se le parole sono state mescolate.
Reti neurali ricorrenti
Le Reti Neurali Ricorrenti (RNN) sono utilizzate in diversi domini. Ad esempio, nell'elaborazione del linguaggio naturale (NLP), per generare testo scritto a mano, eseguire traduzioni automatiche e nel riconoscimento vocale.
A differenze del percettrone multistrato, una rete neurale ricorrente è costruita per gestire input che rappresentano una sequenza, come la sequenza di parole in una recensione. Le reti neurali ricorrenti agiscono come una catena. Il calcolo eseguito ad ogni passo temporale dipende dal calcolo precedente. Lo strato nascosto è in realtà una catena di livelli nascosti, come evidenziato in Figura 1.
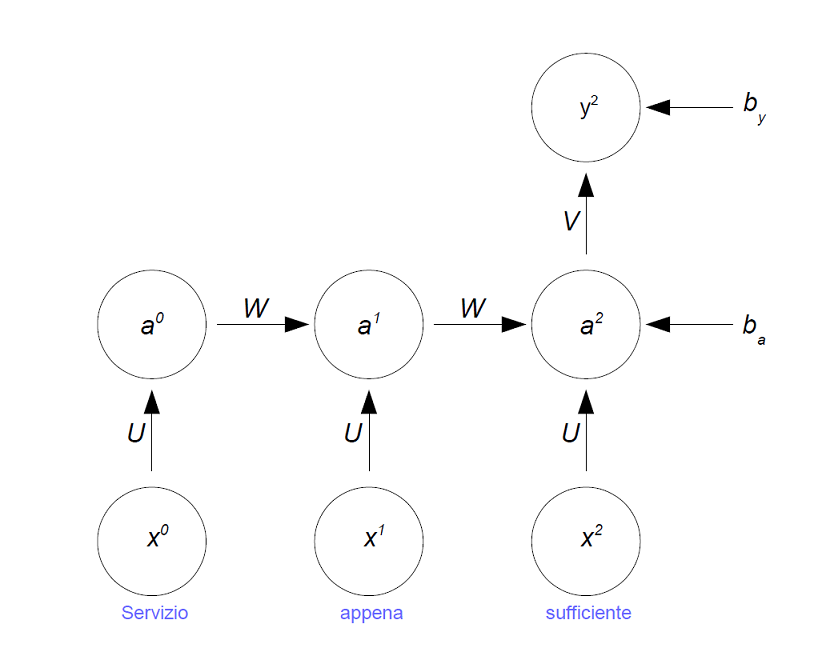
Figura 1: Lo strato nascosto in una RNN è una catena di livelli nascosti
Analogamente ad altri modelli di apprendimento automatico supervisionato, le reti neurali ricorrenti utilizzano una funzione di perdita per confrontare l'output del modello con la risposta attesa. La perdita viene successivamente propagata all'indietro e i pesi del modello vengono aggiornati.
Una caratteristica chiave delle reti neurali ricorrenti è la condivisione dei parametri. Esiste un solo set di parametri utilizzato e ottimizzato in tutte le parti della rete. Se quei parametri non fossero condivisi, il modello dovrebbe apprendere i parametri per ogni parte della sequenza di input e avrebbe molte più difficoltà a generalizzare esempi non ancora visti.
La condivisione dei parametri offre alle reti neurali ricorrenti la capacità di gestire input con lunghezze diverse ed eseguire comunque previsioni in un intervallo di tempo accettabile. I parametri condivisi sono particolarmente importanti per generalizzare sequenze che condividono input, sebbene in posizioni diverse. Le frasi "Ottimo servizio" e "Servizio ottimo", ad esempio, esprimono la stessa opinione utilizzando gli stessi elementi ma combinati in modi diversi.
La condivisione dei parametri implica che la funzione di output è il risultato dell'output dei passaggi temporali precedenti, ogni passaggio aggiornato con la stessa regola. La regola di aggiornamento è la stessa ad ogni passaggio temporale, ovvero la rete applica la stessa funzione di attivazione. Le funzioni di attivazione più comunemente utilizzate nelle RNN sono: Sigmoidea, Tanh e RELU.
Possiamo generalizzare l'esempio di Figura 1, scrivendo le formule per la funzione di attivazione a<t> e per l'uscita y<t> ad ogni passo temporale t:
a<t> = g1(Wa<t-1> + Ux<t> + ba) y<t> = g2(Va<t> + by)
dove W, U, V, ba e by rappresentano i parametri condivisi e g1, g2 le funzioni di attivazione.
Uno degli svantaggi delle RNN è la loro incapacità di poter modellare lunghe sequenze dal momento che le RNN modellano le sequenze come interazioni moltiplicative tra rappresentazioni nascoste di parole. Pertanto, il tentativo di modellare lunghe sequenze porta a gradienti che "esplodono" (tendono a infinito) o "svaniscono" (tendono a zero).
Reti Long Short Term Memory
I fenomeni di "esplosione" o "sparizione" del gradiente si incontrano spesso nel contesto delle RNN. Il motivo per cui si verificano è che è difficile acquisire dipendenze a lungo termine a causa del gradiente moltiplicativo che può diminuire/aumentare esponenzialmente rispetto al numero di livelli.
Le reti Long Short Term Memory (LSTM) forniscono una soluzione al problema della "sparizione" del gradiente delle RNN, modificando l'architettura di queste ultime per stabilizzare l'addestramento. Concettualmente, l'innovazione chiave nelle LSTM è stata la sostituzione delle interazioni moltiplicative delle RNN con interazioni additive. Pertanto, i valori del gradiente non vengono attenuati durante la retro-propagazione poiché sono distribuiti in modo additivo anziché moltiplicativo. Pertanto, nelle LSTM l'entità dei gradienti non svanisce e, di conseguenza, è possibile modellare lunghe sequenze. Tuttavia, le reti LSTM possono ancora soffrire del problema dell'esplosione del gradiente.
ATTENZIONE: quello che hai appena letto è solo un estratto, l'Articolo Tecnico completo è composto da ben 2301 parole ed è riservato agli ABBONATI. Con l'Abbonamento avrai anche accesso a tutti gli altri Articoli Tecnici che potrai leggere in formato PDF per un anno. ABBONATI ORA, è semplice e sicuro.

Ti potrebbe interessare anche:
Pianificazione ottima per un robot E-Puck con feedback visivo

Progetto di un sistema di comunicazioni Wireless Long-Range con LoRa32 – Parte 2
Che cos’è il Transfer Learning e come utilizzarlo
Le nuove frontiere dei dispositivi indossabili
Tecnologie per la fabbricazione di circuiti integrati