Sotto il nome di Continous Integration (CI) vengono raggruppate tutte quelle tecniche e procedure che automizzano l'integrazione di un progetto software. All'interno di questo articolo, verranno descritti brevemente i concetti principali della CI e verrà proposto un esempio pratico di tali concetti tramite il potente strumento software di revisione GIT.
La Continous Integration:
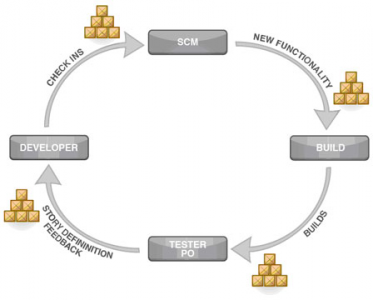
La Continous Integration nasce nel momento in cui l'esigenza di ridurre i tempi di rilascio e il dover convergere il lavoro di sviluppo da parte di diversi team, diventano aspetti predominanti sia in termini di efficienza che di efficacia produttiva. Quindi, essenzialmente l'obiettivo della CI è quello di migliorare la qualità del software implementando un flusso di processi continui che possiamo dividere in quattro step principali:
1)Verificare la presenza di una nuova check in (modifica)
2)Puntare all'ultimo rilascio del codice
3)Eseguire lo script di integrazione della modifica
4)Pubblicare i risultati
Ciascuno di questi step della CI viene implementato e ottimizzato attraverso una macro software.
Come si può intuire dalla descirizione di ciascuno step, lo scopo di ogni singola procedura è quello di fornire uno strumento in grado di determinare in ogni momento, lo stato di salute del codice e di migliorarlo in corso d'opera. Vi sono più tools che implementano questa "filosofia" di programmazione, in questo articolo analizzeremo il GIT.
GIT è un sistema software mirato al “controllo di versione”, realizzato da Linus Torvalds.
Un esempio di software che utilizza tale metodologia è proprio lo sviluppo del kernel di Linux.
Vediamo quali sono le principali scelte implementative che vengono fatte in GIT:
1)Sviluppo distribuito: ciascun developer può avere a sua disposizione l'intero processo di sviluppo o repository. Le modifiche che riporterà potranno essere copiate da una repository all'altra con dei semplici comandi.
2)Velocità e scalabilità
3)Sviluppo non lineare attraverso funzioni di branching e merging.
4)Ogni revisione del codice avviene tramite un commit: esso viene autenticato e crittografato in modo tale che il nome della revisione dipenda dall'intera cronologia precedente. Quindi, non è possibile modificare una commit senza che tale modifica non venga registrata.
5)Quando terminano tutte le modifiche viene effettuato un “merge”: per questa operazione, GIT fornisce più strategie di merge per completare correttamente il merge. Se tutti gl'algoritmi falliscono allora viene sollecitato un merge manuale.
Struttura interna di GIT:
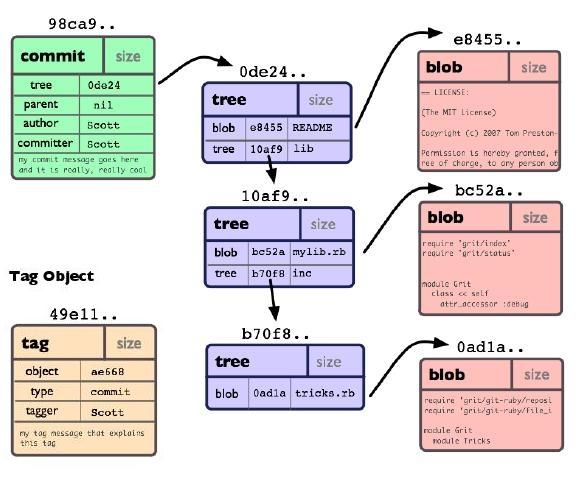
Si può suddividere la struttura interna di GIT in due macro strutture: un indice modificabile in cui viene riportato il contenuto di tutte le informazioni e le modifiche apportate nei vari commit. un database in cui vi sono essenzialmente 4 tipi di oggetti:
--Albero: equivale a una directory in cui troviamo una lista di nomi di file ad essa associata.
--Commit: contiene i riferimenti al nome dell'albero e tutti i metadati che permettono di risalire ai file modificati e al developer che li ha editati. Infatti troviamo ad esempio il nome del committer, data e ora della creazione, un messaggio di log ecc..
--Blob: rappresentano il contenuto vero e proprio dei file. Non hanno nessun data, nome, ora né altri metadati. Git memorizza ogni revisione con un blob distinto. -- Indice: è il punto di collegamento fra il database di oggetti e l'albero di lavoro .
-- Tag:E' un'etichetta in cui si possono memorizzare indicazioni su file o directory inerenti al rilascio dei dati.
Comandi Principali:
Riportiamo di seguito alcuni comandi basilari per utilizzare git:
$ git [command] [option]
$ git [command] -help // per vedere l'help relativo al comando digitato
$ git add
Possiamo poi decidere di modificare ancora il nostro hello_wolrd.c. A quel punto possiamo vedere le modifiche apportate alla repository facendo:
$ git diff hello_world.c //compariranno le differenze tra il file committato in precedenza e quello modificato
$ git status //verifichiamo quali file sono stati modificati
Possiamo poi ripetere i comandi add/commit/format-patch per creare una nuova patch con le modifiche aggiunte.

Ciao, ottimo riassunto.
Ho avuto a che fare con git, però ancora non ho capito come posso estrarre dal repo il progetto alla data o revisione xx.
Ad esempio come si fà a visionare una lista di tutte le revisioni?
All’inizio mi è capitato di fare la seguente fesseria:
git clone…
modifico il sorgente, passano giorni
git checkout
Il checkout mi azzera il repo locale con le mie modifiche, dopo una tale operazione c’è modo di recuperarle? ci vorrebbe una specie di Undo.
Ciao.
Ciao.. per quanto riguarda le revisioni c’ è un modo grafico di visualizzarle..
prova a lanciare gitk ;)..li puoi controllare la cronologia..è un pò difficile da leggere all’inizio ma provaci e vedrai che non te ne pentirai 😉
Poi per quanto riguarda il checkout… se fai modifiche e poi fai il checkout.. a meno che tu non abbia un branch diverso dove hai il codice di prima..penso che allora hai perso tutte le modifiche..
Per questo il mio consiglio è di crearti un branch “master” su cui metti tutta la rep iniziale..dopodichè ad esempio stai creando un nuovo progetto che si chiama pcie allora
ti crei un nuovo branch
git branch pcie
poi “switchi” su quel branch li con:
git checkout pcie
e poi da qui fai tutte le tue modifche..e ovviamente le riporti sul master con un merge quando sei sicuro..dai un’occhiata pure qui : http://book.git-scm.com/3_basic_branching_and_merging.html
Ti dice un pò l’essenziale per fare queste operazioni in modo chiaro..dimmi pure se non ho centrato a pieno il problema oppure se hai altri dubbi !
ciao