
Per soddisfare i requisiti di alta velocità e bassa latenza, sono stati sviluppati nuovi tipi di memoria statica e dinamica: le SRAM QDR e la RLDRAM. Ecco le loro caratteristiche principali ed i criteri di scelta in fase di progettazione.
L’evoluzione delle SRAM per il Networking
Le SRAM sincrone standard, le prime SRAM di massa funzionanti in modalità sincrona, rappresentavano una soluzione ideale per le applicazioni cache. A dispetto della loro diffusione, questi prodotti non sono mai stati molto adatti per le applicazioni di networking, soprattutto per quelle caratterizzate da un profilo abbastanza bilanciato tra operazioni di READ e di WRITE. Un’operazione di READ immediatamente seguita da un’operazione di WRITE provoca infatti uno stato conflittuale del bus dati. Il solo modo per contenere le contese è introdurre dei cicli di “wait” o di “no operation” (NOP) tali da permettere l’inversione del bus. Questi cicli di “wait”, ovviamente, influenzano il livello di utilizzazione del bus, provocando di fatto una riduzione della banda disponibile. Poichè l’utilizzazione della banda rappresenta un fattore determinante, queste SRAM sincrone non sono mai state particolarmente indicate per le applicazioni di networking. Per risolvere il problema delle contese di bus sono state sviluppate le SRAM No Bus Latency (NoBL), note anche come Zero Bus Turnaround (ZBT). Queste SRAM contengono dei registri dati che permettono di eseguire l’accodamento delle operazioni di READ e WRITE, eliminando di fatto i cicli di “wait” e assicurando il massimo livello di utilizzazione del bus. Con l’aumentare delle velocità di linea – arrivate ormai nell’ordine delle decine di gigabit per secondo - si è reso indispensabile individuare e risolvere tutte le problematiche legate alla banda e all’interfacciamento. Nel tempo, sono emerse numerose nuove applicazioni che richiedono non solo una velocità maggiore di funzionamento, ma che impongono anche alla memoria l’esecuzione simultanea delle operazioni di READ e WRITE. Benchè in origine fossero ritenute adatte alle architetture di networking, le SRAM NoBL si sono dimostrate incapaci di stare al passo con le nuove specifiche prestazionali. Da qui è scaturita una nuova generazione di memorie — le SRAM QDR/DDR — nate apposta per indirizzare le esigenze di velocità, densità e banda delle applicazioni di networking più moderne.
La famiglia di SRAM QDR/DDR
Le SRAM QDR e QDR-II – ultima generazione di SRAM sincrone – sono state sviluppare dalle società che fanno riferimento al consorzio QDR (Cypress, Renesas, IDT, NEC e Samsung). La famiglia di SRAM per applicazioni di rete, unitamente alle SRAM Double Data Rate (DDR) e DDR-II, offrono una serie completa di soluzioni di memoria per qualsiasi sistema di networking. Le SRAM QDR e QDR-II sono disponibili con velocità anche superiori ai 300 MHz, con densità da 9 Mb a 72 Mb. L’evoluzione permette di individuare già i nuovi livelli di densità, anche superiori ai 288 Mb. Le SRAM QDR e QDR-II dispongono di porte separate per le operazioni di READ e WRITE, il che permette di evitare qualsiasi contesa di bus. Il termine double data rate identifica il fatto che i dati sono scritti o letti dalla SRAM su entrambi i fronti del clock, raddoppiando di fatto la banda di ciascun pin rispetto alle SRAM convenzionali. La combinazione tra le porte di input e output separate e le interfacce DDR garantisce un incremento di quattro volte della banda totale rispetto alle SRAM sincrone di generazione precedente. Le SRAM DDR e DDR-II appartengono alla stessa famiglia delle SRAM QDR. Esse sono infatti simili alle SRAM QDR e QDR-II SRAM, con la differenza che le SRAM DDR e DDR-II non hanno porte di lettura e scrittura separate. Mentre le SRAM QDR possono eseguire le operazioni di READ e WRITE simultaneamente, i dispositivi DDR possono eseguire solo un READ o un WRITE alla volta. La figura 1 illustra lo schema a blocchi di un dispositivo QDR-II.
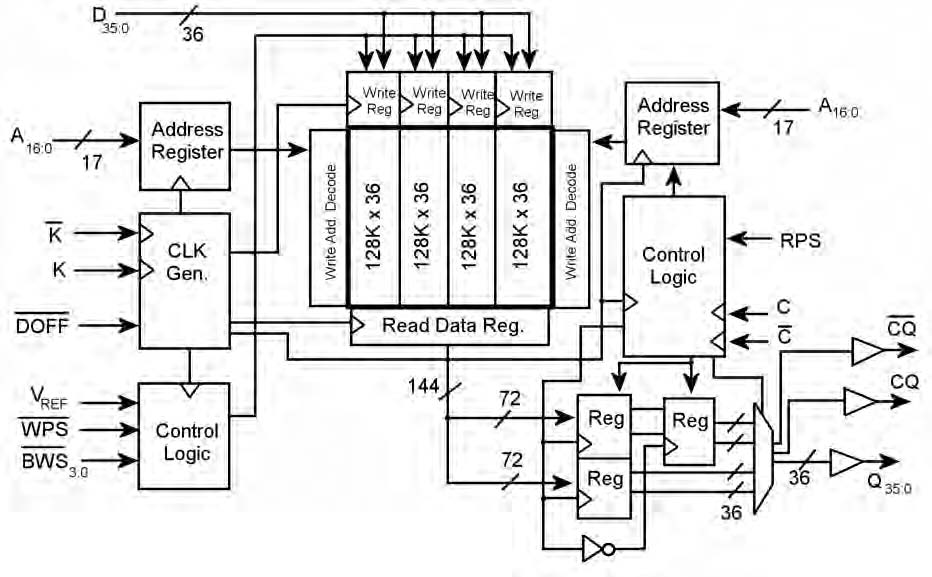 Figura 1. Schema a blocchi di un QDR-II Figura 1. Schema a blocchi di un QDR-II |
A fare delle SRAM della famiglia QDR una soluzione ideale per le applicazioni di networking ad alta velocità concorrono numerose altre caratteristiche, tra le quali:
- Clock di uscita: oltre ai clock d’ingresso K e K#, sono disponibili due clock dati d’uscita, C e C#, che possono essere utilizzati per sincronizzare i dati dalla SRAM. L’uso di questi clock di uscita è opzionale. Con la modalità operativa a clock singolo, il dato è sincronizzato con i clock di ingresso.
- Impedenza di uscita programmabile: le SRAM QDR sono dotate di una circuiteria di impedenza programmabile che permette di regolare il tono del driver d’uscita per adattare l’impedenza della linea di trasmissione. L’adattamento di impedenza migliora l’integrità del segnali.
- Clock di eco: queste SRAM generano una coppia di clock di uscita, CQ e CQ#, che ricalcano fedelmente il dato (allineato sul fronte con i dati). Questi clock servono come clock di uscita dalla SRAM e possono essere utilizzati per eseguire il latching del dato di uscita nel controller. I clock di eco sono disponibili nei prodotti QDR-II, DDR e DDR-II (non nei QDR-I).
La sezione che segue illustra le Reduced Latency DRAM (RLDRAM), sigla che identifica una famiglia di memorie DRAM destinata alle applicazioni di networking.
RLDRAM
Tipicamente, l’array interno di memoria delle DRAM è organizzato in banchi. La locazione di memoria è individuata dagli indirizzi di banco, riga e colonna. Prima di accedere a una particolare riga del banco, il banco stesso (o, più precisamente, la riga) deve essere “aperto” o “attivato” (ciclo #1 in Figura 2).
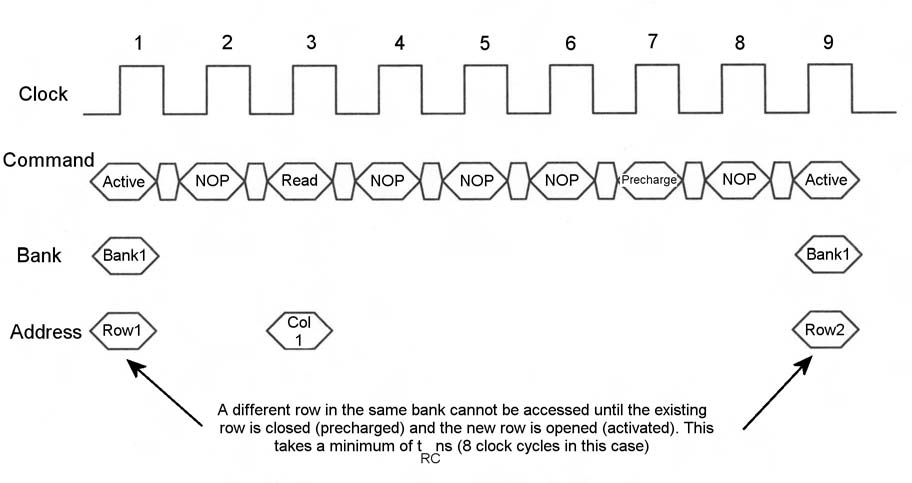
Figura 2: La limitazione trc |
In seguito all’accesso, prima di poter accedere a un’altra riga dello stesso banco, la riga deve essere chiusa o “precaricata”. Così, quando si verificano due accessi a righe differenti dello stesso banco, il banco stesso deve essere precaricato alla fine della precedente operazione (ciclo #7) mentre la nuova riga deve essere attivata (ciclo #9) prima di svolgere l’accesso seguente. Durante questo periodo, il banco non è disponibile per l’accesso. L’indisponibilità di un banco limita la frequenza di accesso al banco stesso. Il ritardo minimo tra due accessi (o attivazioni di banco, come illustrato nella figura) influenza la banda della DRAM. Questa latenza (8 cicli di clock nell’esempio di figura 2), che influenza gli accessi estemporanei al banco, è denominata tempo di ciclo random, periodo “active-to-active”, o latenza “same bank”, ed è identificata - nelle specifiche dei datasheet - con la sigla tRC. Le RLDRAM sono state progettate per indirizzare proprio questi aspetti, invadendo in tal modo il mercato delle SRAM high-bandwidth a bassa latenza. Le Reduced Latency DRAM (RLDRAM) sono soluzioni DRAM sviluppate da Micron e Infineon che permettono di superare le limitazioni di tRC grazie a un’architettura e un’interfaccia migliorative. I dispostivi RLDRAM II utilizzando un’architettura di memoria basata su otto banchi. Le DRAM sono normalmente organizzate su quattro banchi. La configurazione a otto banchi delle RLDRAM aiuta a raggiungere e a mantenere la banda di picco, almeno in determinate condizioni d’uso (discusse successivamente). Più banchi significa anche una maggiore probabilità che un banco sia disponibile per l’accesso — cioè che uno dei banchi possa già essere nello stato di precarica. Questo aumenta la possibilità che il banco a cui si desidera accedere sia effettivamente disponibile. Le RLDRAM II prevedono inoltre un’interfaccia SRAM-like che, rispetto ad altre DRAM, le rende più adatte alle applicazioni di networking. L’indirizzamento del dispositivo è infatti simile a quello di una SRAM: l’indirizzo fornito non deve essere in formato riga-colonna come nel caso delle DRAM standard. In una normale DRAM, l’attivazione di riga deve innescarsi prima di fornire l’indirizzo di colonna, rendendo l’accesso all’array un processo articolato su due fasi. Nelle RLDRAM, con il precaricamento interno e l’attivazione integrata, l’intero indirizzamento avviene in un unico ciclo, rendendo il tutto notevolmente più semplice. Oltre al questo, le RLDRAM II sono equipaggiate con interfacce “double data rate” che consentono il trasferimento dei dati su entrambi i fronti di salita e discesa, raddoppiando la banda rispetto alle soluzioni standard di tipo single data rate. La figura 3 riporta uno schema a blocchi di un’architettura SIO RLDRAM II.
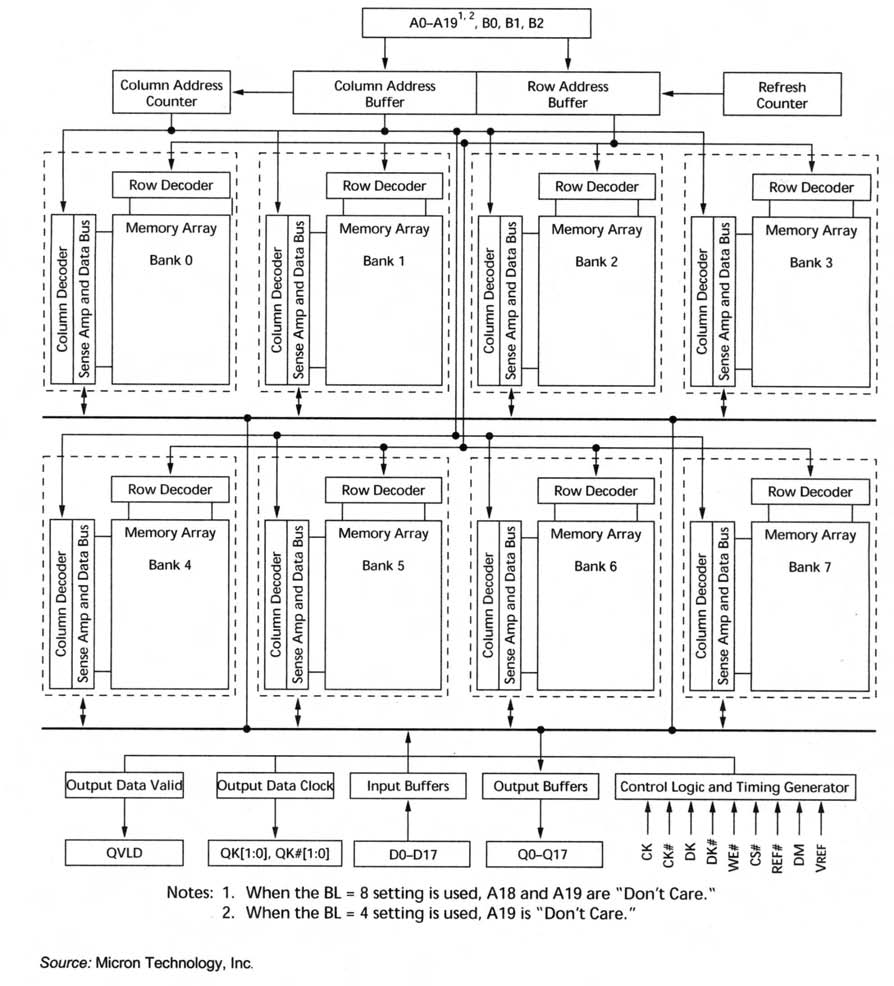 Figura 3: Architettura SIO RLDRAM II Figura 3: Architettura SIO RLDRAM II |
Tra gli altri aspetti di spicco delle RLDRAM II si segnalano i seguenti:
- a somiglianza della famiglia di SRAM QDR/DDR, l’architettura RLDRAM II è disponibile in versioni con I/O separati (SIO) e comuni (CIO). L’architettura RLDRAM II SIO consente letture e scritture simultanee come le QDR, mentre l’architettura CIO è simile a quella delle SRAM DDR.
- Oltre ad avere un indirizzamento simile a quello delle SRAM, le RLDRAM possono sfruttare anche lo schema multipelxato delle DRAM tradizionali grazie a un’appropriata predisposizione nel registro di modalità. Questa caratteristica consente alla RLDRAM di essere compatibili, in termini di indirizzamento, con i progetti di controller della generazione precedente e di ridurre il numero di pin di indirizzamento utilizzati dal memory controller.
- un segnale di uscita, il “data valid signal”, indica che i dati presenti sulle linee di I/O sono da leggere.
- Il progetto RLDRAM II sfrutta inoltre dei clock di data strobe. Si tratta di una coppia di clock liberi per il latching dei dati di uscita (simili ai clock di eco CQ e CQ# delle QDR-II).
Benché solo in particolari condizioni di accesso o di indirizzamento, l’architettura RLDRAM II è in grado di raggiungere una banda utile del 100%. Come sopra menzionato, le linee di indirizzamento delle RLDRAM non devono essere multiplexate (indirizzi di riga/banco e colonna non devono essere impostati in tempi differenti). Quindi, utilizzando i bit meno significativi (LSB) delle linee di indirizzo per riferirsi al banco e sfruttando una tecnica di round-robin, è possibile assicurare che lo stesso banco non venga interrogato per uno specifico periodo di tempo. Ciò significa che utilizzando gli LSB delle linee di indirizzo dal controller come ingressi di banco alla RLDRAM (pin B0, B1 e B2) e incrementandone il valore è possibile avere un accesso a un banco differente in occasione di ciascun ciclo di un determinato periodo di tempo. Se questo periodo è superiore o uguale al tempo di ciclo random (tRC), come illustrato in figura 4, il tRC non limiterà più la banda del dispositivo, che sarà così utilizzabile totalmente.
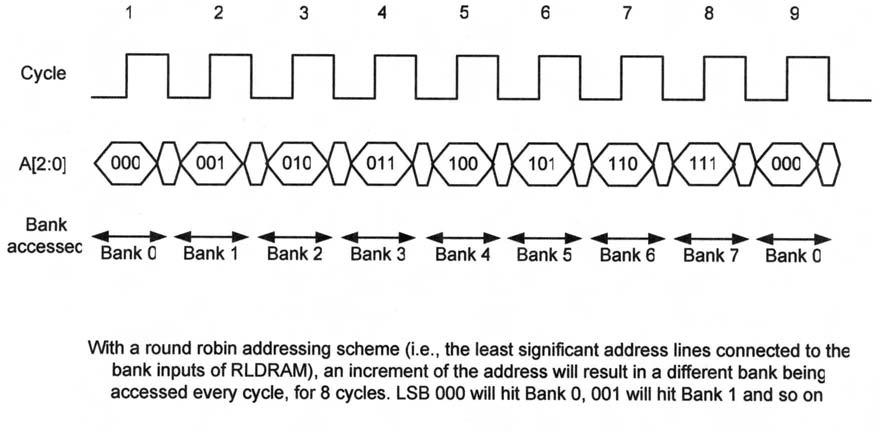
Figura 4: Accessi sequenziali per l'indirizzamento di una RLDRAM |
Questa tecnica di indirizzamento “round robin” può essere vantaggiosa quando gli accessi alla memoria dal controller sono sequenziali. Nelle applicazioni di networking però, gli accessi ai dati sono di natura random, perciò anche l’accesso ai banchi può essere imprevedibile. Ciò significa che l’utilizzo della tecnica di routing round-robin per accedere alla RLDRAM può non essere una soluzione efficace e può anzi comportare che uno stesso banco sia interrogato prima della scadenza del tRC, provocando un’anomalia di accesso. Quindi, il tRC può limitare la banda delle RLDRAM II in situazioni in cui i pattern dati siano imprevedibili. Un altro punto da considerare è la lunghezza dei treni di accesso (burst). Una lunghezza maggiore comporterà più tempo per un nuovo accesso. Quindi, se viene utilizzato un dispositivo con lunghezza di burst elevata, per coprire la latenza di tRC sarà necessario accedere a meno banchi; con un dispositivo con lunghezza di burst ridotta, per ottenere il massimo di banda dovranno essere utilizzati più banchi alternativamente.
Confronto tra SRAM QDR e RLDRAM
Dopo avere analizzato le differenze architetturali tra le due soluzioni di memoria ad alta velocità, passiamo a esaminare la loro validità nelle differenti circostanze.
Randomicità delle applicazioni:
Benchè in specifiche sequenze di accesso le RLDRAM II possano raggiungere un livello totale di utilizzazione della banda grazie allo schema di indirizzamento round-robin, esse non sono così efficaci quando l’accesso ai dati è random. Nonostante le dotazioni architetturali delle RLDRAM II - per esempio la disponibilità di più banchi interni e l’uso di meccanismi integrati di precarica e di attivazione (che riducono il tRC) - esse non permettono di evitare completamente la latenza e i suoi effetti sulla banda. La forma d’onda in figura 5 mostra come la latenza tRC influenzi la banda in presenza di burst corti e laddove il pattern dati sia imprevedibile. Per un secondo accesso al banco A si devono infatti attendere vari cicli prima che il tRC sia scaduto, lasciando così il bus inutilizzato. In questi casi, la banda delle architetture RLDRAM è limitata dalla natura imprevedibile degli accessi ai dati. In confronto, le SRAM QDR non sono gravate da alcuna latenza tra due accessi e sono quindi meno influenzate dalla natura random delle applicazioni. Esse raggiungono un livello totale di utilzzazione della banda disponibile indipendentemente dalla sequenza di accesso o dall’indeterminatezza del pattern dati.
Latenza iniziale:
Le RLDRAM II hanno una latenza iniziale notevolmente superiore a quelle delle SRAM QDR (come illustrato in figura 5). SRAM QDR e QDR-II hanno una latenza iniziale di READ rispettivamente di soli 1.0 e 1.5 cicli di clock quindi, durante un burst, il primo segmento di dati esce molto prima nelle SRAM QDR che nelle RLDRAM II. Questo rende le SRAM QDR ideali per le applicazioni a bassa latenza. Nelle RLDRAM II, l’elevata latenza iniziale è un problema quando si verificano degli accessi back-to-back a dati corti. La figura 5 mostra anche come burst di lunghezza ridotta possano limitare l’utilizzazione di banda delle RLDRAM II.
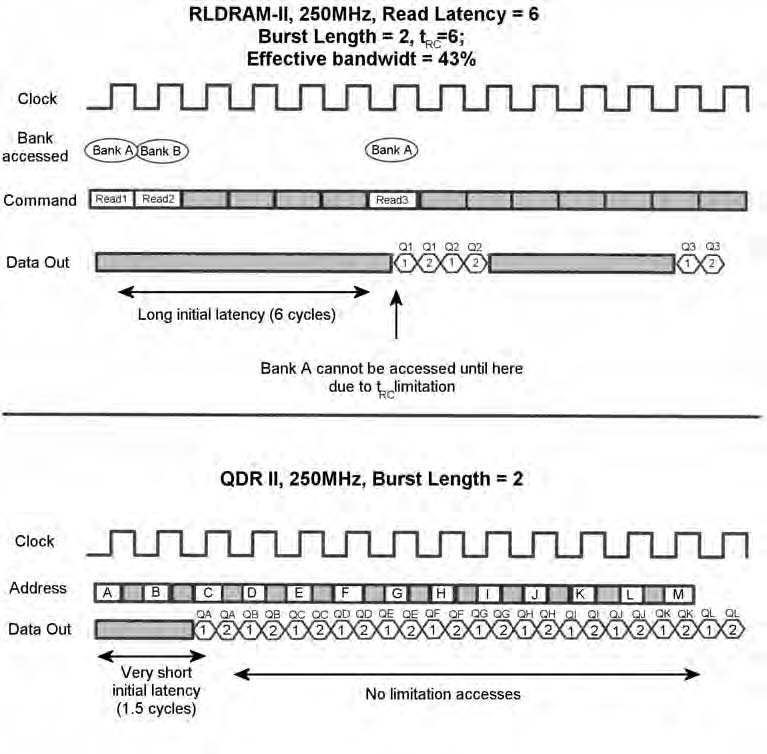 Figura 5: Influenza della latenza tRC sulla banda Figura 5: Influenza della latenza tRC sulla banda |
In confronto, a determinate frequenze, la banda delle SRAM QDR (o DDR) non è influenzata dalla lunghezza del burst.
Densità e Costi:
Quando si decide il tipo di memoria da utilizzare, se la densità e il costo per bit rappresentano considerazioni più importanti rispetto alla indeterminatezza dell’applicazione e all’utilizzazione continua della banda di picco. Le RLDRAM possono garantire una valida opzione grazie alle ridotte dimensioni della loro cella di memoria (1T).
Utilizzazione bus:
Nella scelta della memoria più adatta, l’utilizzazione del bus rappresenta un parametro chiave. La figura 6 illustra l’aspetto seguente.
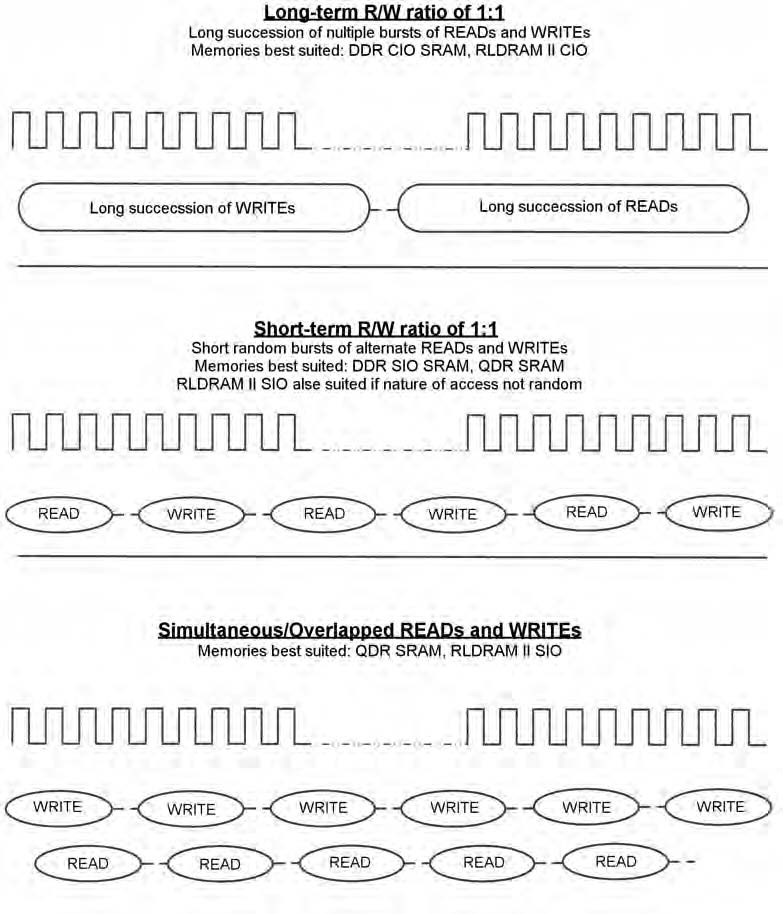 Figura 6: Vari esempi di pattern READ/WRITE Figura 6: Vari esempi di pattern READ/WRITE |
Alcuni sistemi possono avere un rapporto a “breve termine” tra operazioni di READ e di WRITE di 1:1. questo significa un numero ridotto di READ e WRITE, spesso interallacciati tra loro. In tali sistemi, l’inserimento di cicli di dummy per l’inversione dei bus comporta la perdita di un numero significativo di cicli, con un pessimo effetto sulla banda. In queste condizioni, SRAM DDR SIO, QDR o RLDRAM II SIO rappresentano la scelta migliore. Viceversa, i dispositivi CIO quali SRAM DDR e RLDRAM II sono più indicati in applicazioni che hanno un rapporto di READ e WRITE di 1:1 a “lungo termine”, cioè con READ e WRITE che si distribuiscono su burst lunghi. Se READ e WRITE si verificano un lunghe sequenze senza alternarsi frequentemente, il numero di cicli persi per superare le contese di bus sono estremamente ridotti rispetto al numero di cicli utilizzati per le operazioni di lettura e scrittura. Questo rende i dispositivi CIO – quali le SRAM DDR o le RLDRAM II CIO – un’opzione particolarmente valida. In tali applicazioni, la scelta di un dispositivo SIO comporterebbe uno spreco di I/O per una porzione significativa dei cicli. Un terzo possibile scenario è quando READ e WRITE si verificano simultaneamente. In questi sistemi la scelta ideale sono i dispositivi SIO, quali le SRAM QDR e le RLDRAM II SIO. Riassumendo, per scegliere la soluzione di memoria più adatta in termini di architettura di I/O è necessaria un’approfondita analisi delle esigenze dell’applicazione relative all’utilizzo del bus. La figura 6 riporta i differenti pattern di READ/WRITE e quali memorie sono più indicate.
La grande decisione: scegliere la memoria più adatta
Con una così vasta proposta di memorie sincrone ad alta velocità, il compito dei progettisti di sistemi chiamati a scegliere la soluzione è più adatta alle loro esigenze è piuttosto arduo. Le schede di linea normalmente hanno bisogno di varie memorie per le differenti funzioni (per esempio, lookup tabelle, buffering dei pacchetti e gestione code). Benchè tutte queste funzioni necessitino di una memoria ad alta velocità, non tutte le memorie per networking sono adatte. Questa sezione descrive le differenti specifiche di memoria di una scheda di linea e le soluzioni che meglio si adattano a ciascuna applicazione. La figura 7 è una rappresentazione ad alto livello di una tipica scheda di linea.
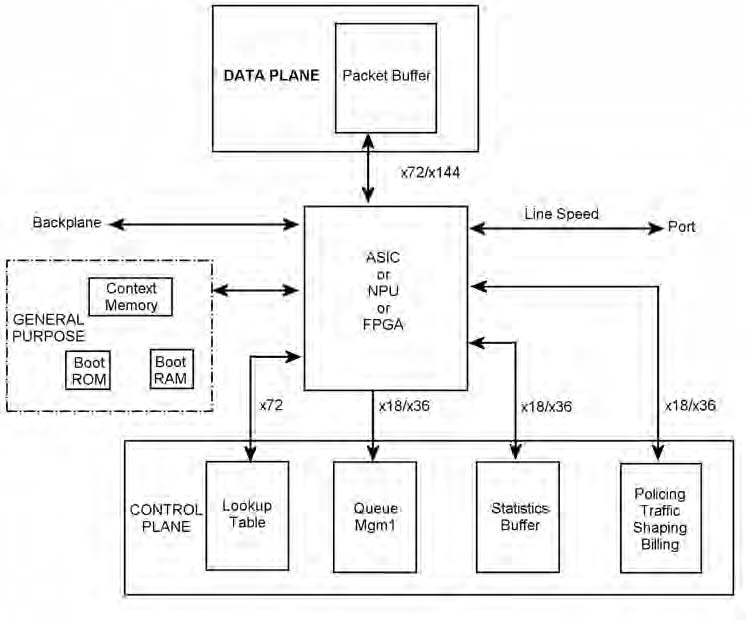 Figura 7: Tipica struttura di una interfaccia di comunicazione Figura 7: Tipica struttura di una interfaccia di comunicazione |
La tabella di look-up esegue la traslazione degli indirizzi in fase di routing dei pacchetti. Gli accessi di memoria alla tabella di look-up sono spesso random e caratterizzati da brevi treni di operazioni di READ. Per questo, la latenza rappresenta il fattore più critico per la scelta della memoria. Più recentemente, grazie alla capacità dei router di gestire una grande mole di entry, anche le densità sono diventate un fattore importante. Benchè la soluzione di memoria ideale per le tabelle di look-up possa variare da un’architettura all’altra, in generale la famiglia di SRAM QDR/DDR garantisce numerosi vantaggi. Come illustrato precedentemente, le SRAM QDR vantano una latenza di lettura molto più breve rispetto alle RLDRAM. Questo le rende più adatte alle tabelle di look-up, le quali sono dominate da brevi burst di READ e hanno perciò bisogno di accessi più rapidi. Oltre a questo, la natura random dell’applicazione e i tempi di inversione del bus durante i burst brevi rappresentano fattori critici che rendono le SRAM QDR la scelta migliore per le tabelle di look-up. D’alta parte, laddove le tabelle di look-up sono ampie e l’aspetto finanziario è critico, le RLDRAM II – grazie alla loro bassa latenza, all’alta densità e al basso costo – rappresentano la scelta più conveniente.
Gestione code e pacchetti:
Gestione code e controllo flusso sono funzioni caratterizzate da operazioni di lettura e scrittura random. Anche in questo caso, la latenza in presenza di pattern dati imprevedibili costituisce un fattore critico da considerare in fase di scelta della memoria. Il confronto tra le latenze di SRAM QDR SRAM e RLDRAM II rivela che la SRAM QDR garantisce prestazioni nettamente superiori rispetto alle DRAM per networking, in particolare quando i pattern dati sono imprevedibili. Le imperfezioni delle RLDRAM II durante le operazioni random di READ e WRITE sono state già illustrate. In applicazioni quali la gestione delle code, laddove la densità non è un fattore determinante ma la latenza lo è, le SRAM QDR rappresentano la scelta migliore.
Buffer statistiche:
I buffer per le statistiche gestiscono i dati tariffazione, diagnosi e numerose altre informazioni. Durante l’elaborazione dei pacchetti, l’accesso ai dati statistici deve essere rapido e deve quindi assicurare una bassa latenza. Di contro, i dati statistici normalmente non sono grandi, quindi le operazioni sono caratterizzate da burst brevi o del tutto assenti. Sia le SRAM QDR sia le SRAM NoBL sono particolarmente indicate per queste operazioni.
Buffer Packet Cell:
Il buffer pacchetti nel livello dati è utilizzato per memorizzare i pacchetti nelle porte di uscita e nella matrice di commutazione mentre i pacchetti stessi vengono elaborati. In funzione della velocità di elaborazione dell’ASIC o dell’NPU, la memoria associata al buffer pacchetti deve garantire doti adeguate di velocità, densità o entrambe. Nei progetti dove la latenza è un aspetto critico, sono da preferire le SRAM QDR mentre le RLDRAM II sono una soluzione valida laddove la densità è importante.



Il design di memorie e’ molto complicato, bisogna tener in mente diversi fattori, in primis velocita’ e consumo. Da qui ai prossimi anni dovremmo assistere ad un deciso miglioramento in termini di latenza.
Dettagliatissimo! Nel mio piccolo: finalmente ho capito cosa significa DDR e cosa sono i timings